도서관 자리 예약하기

Python으로 도서관 자리 예약시스템 만들기
나는 어릴 때 부터 도서관을 좋아해서 책을 읽거나 공부하러 자주 가곤하는데 최근에 집에서 가장 가까운 도서관이 증축공사로 인해 문을 닫아서 두번째로 가까운 거리에 있는 도서관에 다니게 되었다. 그런데 나와같은 사람이 많아서 그런지 사람이 엄청 많다. 아마 얼마남지 않은 수능과 공무원시험, 그리고 최근의 무더운 날씨가 주된 이유인 것 같다.
책이 있는 자료실은 비교적 한산해서 아무때나 자유롭게 이용할 수 있는데, 열람실과 디지털 자료실은 내가 가는 시간대에 항상 사람이 많았다. 언젠가는 20분을 기다려도 자리가 나질 않아서 그냥 돌아온적도 있었다.
그러다가 도서관 홈페이지에 들어가보니 현장 예약만 되는줄 알았는데 원격으로 좌석을 예약할 수 있는 서비스가 있는 걸 발견했다. 하지만 매일매일 들어가서 예약하는걸 항상 잊어버리고 무엇보다 매우 귀찮기 때문에 다음날 좌석을 자동으로 예약을 해주는 프로그램을 만들기로 했다.
What is purpose?
나는 보통 도서관에서 랩탑을 이용하기 때문에 랩탑사용이 가능한 디지털자료실을 예약하도록 한다.
디지털자료실에는 좌석의 종류가 있는데 그중 노트북 유저를 위한 코드가 있는 자리는 약 30석 정도가 있는것 같다. 하지만 다섯자리를 제외한 나머지는 예약할 수 없는, 그냥 자리가 비어 있으면 앉는 오픈형이다. 따라서 예약가능한 한자리를 예약해놓는 프로그램을 제작한다.
Analysis
우선 서비스가 어떻게 구성되어있는지 봐야한다.
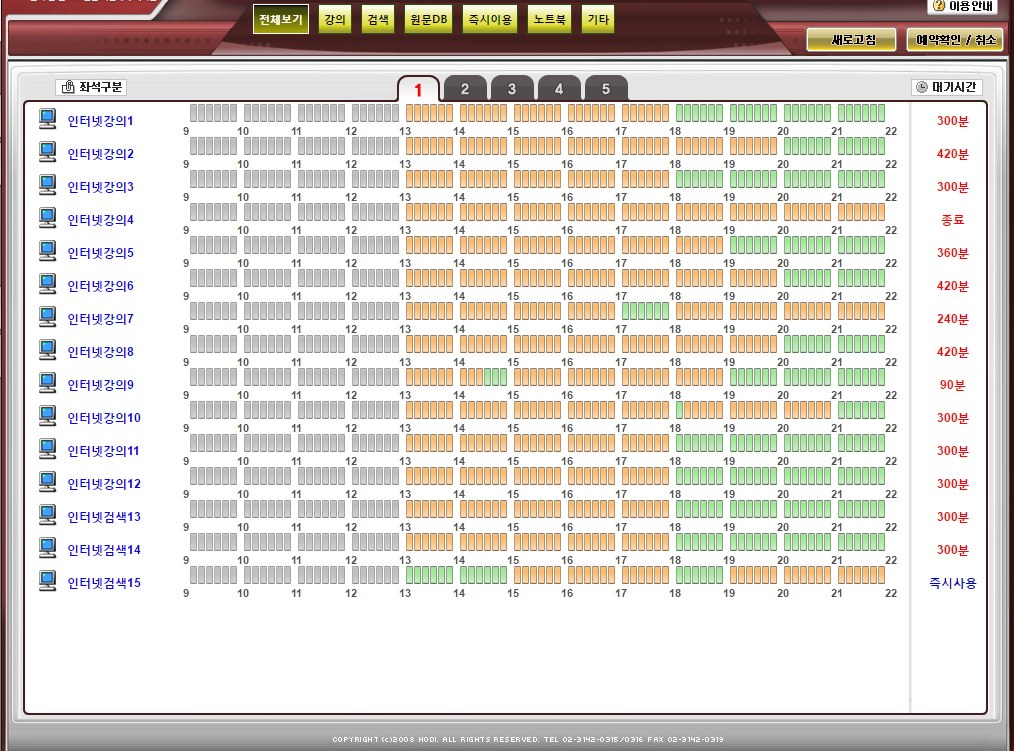
여기서 초록색 막대기가 있는 자리가 비어있는 자리이고 누르면 해당 좌석에 대해 예약할 수 있는 팝업이 뜬다.
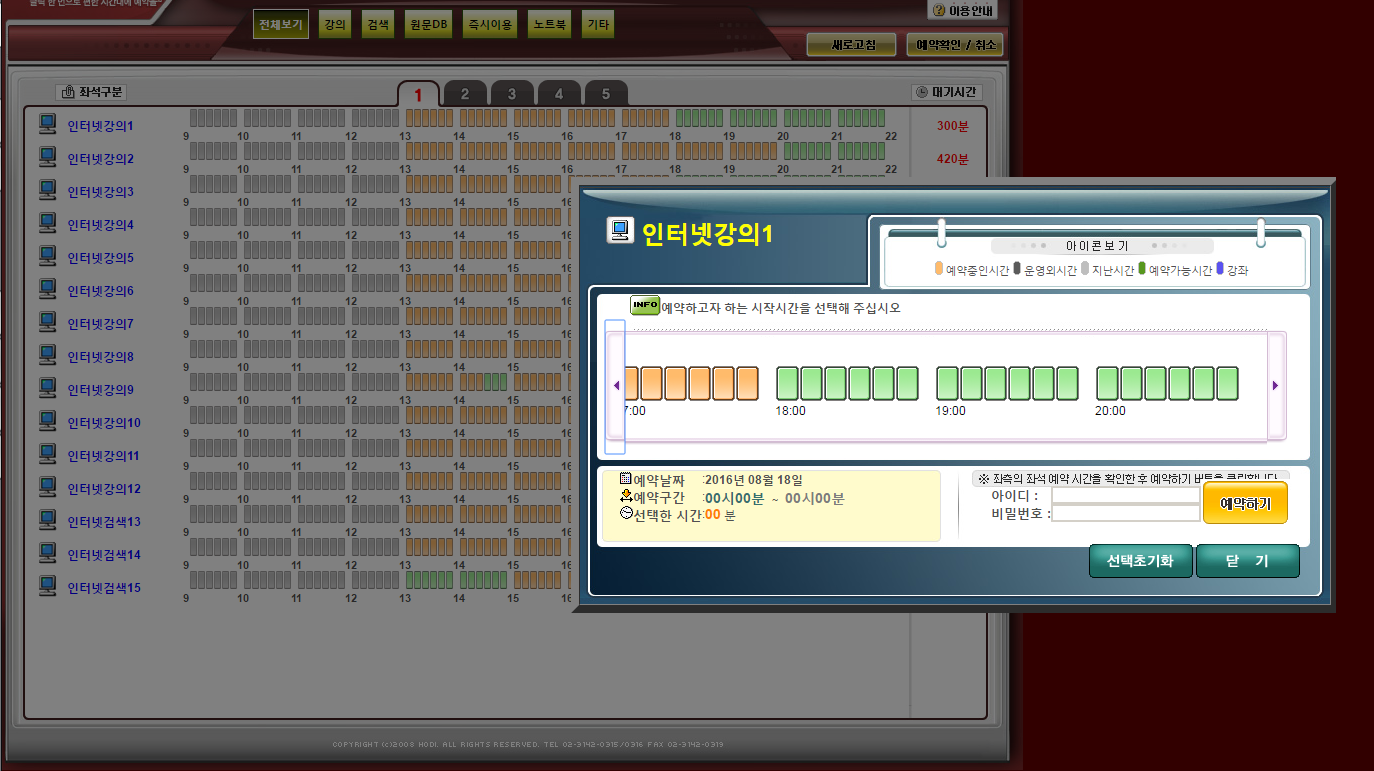
그리고 타임라인에서 예약할 시간대를 선택한 후 아이디와 비밀번호를 적고 예약하기 버튼을 누르면 예약이 완료된다.
개발자도구를 통해서 자세히 보면 서버는 php로 구현되어있고 데이터만 보내주는 식이 아니라 렌더링 된 상태로 오는 것 같았다.
빈 좌석을 누르면 팝업이 뜨는데, 좌석의 id와 팝업창에서 보여줄 시간대를 쿼리스트링으로 넘겨서 다시 응답을 받아 오고있다. 그리고 예약할 때 form을 포함해서 POST요청을 보낸다. field는 다음과 같다.
// form field
// 좌석별 id, 1~30 : 인터넷 검색, 45~48 : DVD, 52~53 : 어학기, 67~71 : 노트북
seat_id:
// 9:00 => 19, 21:50 => 96, 10분 간격으로 예약가능, 사람당 최대 예약시간은 3시간
// 따라서 Hevar - Hsvar < 18
Hsvar: // 시작시간
Hevar: // 끝시간
// 시작시간, EtimeVar은 무조건 00으로 주고있음
StimeVar:
EtimeVar:
// 무슨 파라메터인지 모르겠으나 안줘도 POST요청이 정상적으로 처리되는것을 확인.
bars:
dayAct:
//아이디, 패스워드
Userid:
Userpw:
그래서 할일을 정리하면,
- 빈 좌석을 찾는다.
- 동적크롤링이 필요한 상황이 아니기 때문에 가상브라우저를 사용하지 않아도 된다. 따라서 예전에 사용해 본적이 있는 bs4를 사용하도록 한다.
- 예약이 가능 한지 확인하고 예약요청을 보낸다.
- 예약 가능 여부를 체크하고 form에 포함되어야 할 파라미터를 뽑는다.
- 어떤좌석을 예약했는지 나에게 알려준다.
- python 내장 라이브러리인 smtplib와 구글의 smtp서버를 사용한다.
- 매일 반복한다.
- 리눅스용 작업스케쥴러인 crontab을 이용한다.
Seat state crawling
페이지를 뜯어 보면 iframe이 박혀있었다.
가운데의 좌석정보를 알려주는 프레임은 '/Vorvertrag_Position.php’로 iframe링크가 걸려있다. 이곳에 파라미터를 넘기면 어떤 좌석이 비어있는지 보여주는 html이 온다.

페이지를 가져오기 위해 requests와 beautifulsoup4를 설치한다.
npm install requests, beautifulsoup4
그리고 간단한 코드로 페이지를 파싱할 수 있다.
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
seatNum = 1 # 가져오려는 좌석 아이디
page = lambda seatId: requests.get('http://210.104.8.144:8800/Libmate3_web_hj/Vorvertrag_Position.php?id=' + str(seatId) + '&t=1&s=1')
soup = BeautifulSoup(page(seatNum).content, "html.parser")
이렇게 페이지를 가져오면 이제 해당 페이지의 DOM을 traversing 할 수 있다.
만약 좌석이 비어있다면 초록색 막대 이미지인 /images/range/bar_green.gif로 이미지가 링크된다. 또한 고맙게도 이미지 태그에 alt값으로 '17:50’같이 해당하는 시간이 표시되어 있다. 덕분에 다시 상위 태그로가서 좌석의 id를 가져오는 수고를 하지 않아도 된다.
mySoup = soup.find_all("img", {"src": './images/range/bar_green.gif'})
find_all 메소드를 통해서 원하는 attribute가 포함된 태그를 찾을 수 있다. 이 외에도 정규식을 포함한 다양한 기능을 지원한다.
공식 도큐먼트에 설명이 잘 되어있다.
Send request for reservation
원하는 좌석과 시간을 받아서 자리를 예약하는 요청을 보내준다. 매일 같은 자리면 식상하기 때문에 같은 타입의 좌석중 랜덤으로 선택한다.
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import random
from config import reservation_limit, library_id1, library_password1, library_id1, library_password1
# 시간을 form에 포함할 파라미터로 바꿔줌
def time_parser(time):
divide = map(int, time.split(':'))
minute = divide[0]*60 + divide[1]
return minute/10 - 35
# 비어있는 좌석 하나를 선택. time은 hour:minute 형태의 string
def form_maker(seatType, time):
result = {}
while seatType:
# 자리 하나를 랜덤으로 선택
seat_num_today = random.choice(seatType.keys())
extra_time = map(time_parser, seatType.pop(seat_num_today))
# 3시간 예약이 가능한가?
for i in range(0, reservation_limit):
if time_parser(time) + i not in extra_time:
seat_num_today = False
break
if seat_num_today:
result['seat_id'] = seat_num_today
result['Hsvar'] = time_parser(time)
result['Hevar'] = result['Hsvar'] + reservation_limit
result['StimeVar'] = time.replace(':', "")
result['EtimeVar'] = '00'
result['Userid'] = library_id1
result['Userpw'] = library_password1
result['bars'] = '1700'
break
return result
# name : 원하는 좌석의 종류, time : 원하는 시간
def main(name, time):
# 좌석 초기화
seatTypes = {
'searchInternet': dict(zip([str(i) for i in range(1, 31)], [''] * len(range(1, 31)))),
'dvd': dict(zip([str(i) for i in range(45, 49)], [''] * len(range(45, 49)))),
'linguistics': dict(zip([str(i) for i in range(52, 54)], [''] * len(range(52, 54)))),
'notebook': dict(zip([str(i) for i in range(67, 72)], [''] * len(range(67, 72))))
}
# 빈 좌석을 알아내기위한 url, 팝업에서 여기로 iframe이 걸려있음.
page = lambda seatId: requests.get('http://210.104.8.144:8800/Libmate3_web_hj/Vorvertrag_Position.php?id=' + str(seatId) + '&t=1&s=1')
for seatType in seatTypes:
for seatNum in seatTypes[seatType]:
remain = []
soup = BeautifulSoup(page(seatNum).content, "html.parser")
# 빈좌석이라면 bar_green.gif 임. img 태그 객체를 return
mySoup = soup.find_all("img", {"src": './images/range/bar_green.gif'})
for imgObj in mySoup:
try:
remain.append(imgObj['alt'])
except:
print 'occur parsing error where handling for ' + imgObj['alt']
currentType = seatTypes[seatType]
currentType[seatNum] = remain
formField = form_maker(seatTypes[name], time)
if formField:
requests.post("http://210.104.8.144:8800/Libmate3_web_hj/Vorvertrag_Sql.php", data=formField)
return
if __name__ == "__main__":
main('notebook', '19:00')
Confirm reservation
어떤자리에 예약을 했는지 알아야 하기 때문에 예약을 한 결과를 내가 받아야 한다.
그런데 예약요청에 대한 응답또한 데이터만 오지않는다. 여기선 요청에 대한 response가 열려있던 예약팝업창에서 특정 태그의 내용을 바꿔주는 스크립트를 실행 시키는 방식으로 구현되어 있다. 동일한 방법으로 받은 데이터를 파싱 할 수 있지만 귀찮기 때문에 response body를 통째로 내 메일로 보내도록한다.
구글의 SMTP서버를 사용하면 구글아이디와 비밀번호를 통해서 smtp서버에 로그인 할 수 있다. 또한 파이썬 내장라이브러리중 MIME과 관련된 라이브러리들을 사용하면 복잡한 메일관련 헤더설정을 편하게 할 수 있다.
import smtplib
from config import gmail_id, gmail_password, smtp_server, smtp_port
from email.mime.text import MIMEText
def email_myself(msg):
msg = MIMEText(str(msg))
me = 'ho1234c@gmail.com'
msg['Subject'] = 'confirm reservation'
msg['From'] = me
msg['To'] = me
# smtp_server = mail.smtp2go.com
# smtp_port = 2525
session = smtplib.SMTP(smtp_server, smtp_port)
session.ehlo()
session.starttls()
session.login(gmail_id, gmail_password)
smtpresult = session.sendmail(me, [me], msg.as_string())
session.quit()
if smtpresult:
return False
else:
return True
ehlo : 클라이언트가 SMTP서버에게 통신을 시작할 것임을 알리는 커맨드.
starttls : 암호화되지 않은 plain text는 도청되기 쉽다. plain text의 커뮤니케이션에 사용되는 프로토콜을 확장해서 연결을 암호화시켜준다.
Run regularly
사실 처음엔 pythonAnywhere를 이용하려고 했으나 free tier에서는 자체적으로 정해놓은 whitelist에 포함되는 url에만 접근이 가능했고, 당연히 우리집앞 도서관은 whitelist에 등록되어있지 않기 때문에 접근이 제한되었다. 그래서 아깝지만 AWS의 EC2를 사용하기로 했다.
리눅스 작업 스케쥴러인 crontab은 -l 옵션으로 현재 예약되어있는 스케쥴을 볼 수 있고 -e 옵션으로 스케쥴을 수정 할 수 있다. 아래와 같은 양식으로 지정해 줄 수 있다.
* * * * * path
| * | * | * | * | * | path |
|---|---|---|---|---|---|
| 분 | 시 | 일 | 월 | 요일 | 경로 |
| 0-59 | 0-2 | 1-31 | 1-12 | 0-6(0,6:일요일) |
작업 로그는 /var/log/cron 에 기록된다.
주의할점은 crontab의 데몬은 기본 환경과 달라서 환경변수 경로를 지정해 줘야 한다.
도서관 사서분께 문의한 결과 예약시스템은 당일 00시부터 가능하다고한다. EC2의 서버시간은 UTC기준으로 맞춰져 있다. UTC 시간은 영국 그리니치 천문대(경도 0)를 기준으로 하는 세계의 표준시간대로, 우리나라보다 9시간이 느리다. 수강신청처럼 촌각을 다투진 않을것 같기 때문에 우리나라 시간으로 00시 1분, 서버시간으로 15시 1분에 실행시키도록한다.
# path
PATH=/usr/local/bin/:/sbin:/bin:/usr/sbin:/usr/bin
# run
1 15 * * 0-4 python /home/ec2-user/request.py
마치며…
이로서 부지런한 도서관 피플들과 경쟁할 준비가 되었다. 사실 매일 들어가서 예약을 해도 되고 채 3분도 걸리지 않을거지만 그게 왜 이렇게 귀찮은지 모르겠다. 귀찮음이 프로그래밍의 가장 큰 동기인것같다.